

Машинное обучение в Embedded системах. Часть 1
Вступление
Я внимательно слежу за всей шумихой в области машинного обучения, и только в 2019 году наконец-то смог сказать, что технология созрела настолько, чтобы ее стало можно применять во встроенных решениях низкого/среднего уровня. (Не стоит сразу бросаться применять новую технологию как универсальное решение, но инженерам нужно следить за тем, что окажется ценным в будущем или может вырасти во что-то, что можно будет использовать на практике. В то же время, разработчикам стоит подождать, пока «ажиотаж» исчезнет, а затем выбрать действительно ценную информацию). Теперь я наконец-то вижу, что сейчас самое время заняться машинным обучением более серьезно, т.к. инструменты и платформы уже достаточно зрелые и простые в использовании.
Во всяком случае, я решил сделать совершенно примитивный проект, чтобы оценить ограничения и варианты использования ML в мире встроенных решений. Поймите меня правильно, это не исследование, а просто оценка текущего состояния инструментов и того, как они работают с существующими технологиями с низким порогом входа. Сейчас, если разработчики услышат слово embedded, многие из них подумают о каком-то ARM процессоре, который работает под управлением Linux на SBC. Ну, конечно, это то же встроенное решение, и в наши дни используется множество таких SBC, и они действительно дешевы, но встроенными являются также и очень дешевые 8, 16, 32-битные RISC микроконтроллеры или серия Cortex-M.
Давайте в рамках этого цикла статей, примем несколько предположений. Давайте будем считать, что низкий уровень встраиваемых решений - это контроллеры уровнем до Cortex-M включительно, а высокий уровень - все остальные микроконтроллеры и микропроцессоры, на которых фактически можно работать под Linux. Я знаю, что есть также небольшие микроконтроллеры без MMU, которые могут работать под Linux, но давайте забудем об этом сейчас. Кроме того, для удобства я буду называть машинное и глубокое обучение термином ML. Хотя терминология в этой области уже устоялась, я пока ее несколько упрощу, даже если в некоторых случаях она будет не совсем верна. В противном случае эта статья станет похожей на те, которые я читал сам в начале эры ML, которым практически невозможно следовать. Итак, хотя между терминами и есть некоторые различия, давайте все пока упростим. AI, глубокое обучение, машинное обучение ... Я буду называть все это ML! В рамках статьи одиночный нейрон будет иногда называться узлом, а нейронная сеть сокращаться до NN.
Цикл будет разбит примерно на 5 статей. В первой из них я дам очень общую информацию о ML и NN; без погружения в детали. Также в этой статье мы реализуем очень простую NN с одним узлом с 3 входами и 1 выходом, а затем запустим несколько тестов на различных MCU и проанализируем результаты.
Во второй части я буду использовать те же MCU, но запущу более сложную NN, которая будет иметь те же входы, но добавится скрытый уровень с 32 узлами и 1 выходом. Эта NN будет более точной в своих предсказаниях (как мы увидим) по сравнению с простой NN; но в то же время потребует больше времени на обработку. Из статьи вы вряд ли узнаете терминологию или подробности о ML, скорее наоборот, вам гораздо проще будет ее читать, если вы уже имеете понятие о NN.
Ну, и не забывайте, что это примитивный проект, имеющий чисто познавательную цель. Итак, двигаемся дальше.
Компоненты
В этом проекте я использовал множество различных плат для выполнения этих тестов, и, что интересно, я смог протестировать все эти платы с одним и тем же кодом. Конечно, возможно, прошивка для stm32f103 (blue-pill) была более оптимизированая, так как я использовал свой собственный шаблон cmake низкого уровня, но, тем не менее, мне очень понравилось, что на большинстве моих плат может быть выполнен один и тот же код для нейронной сети. Итак, вот перечень протестированных плат:
- STM32F103C8T6 (blue-pill)
Это моя любимая плата. Я запустил тесты на 72 МГц, а затем разогнал MCU до 128 МГц. - STM32F746G
Микроконтроллер установлен на плате STM32F746GDISCOVERY, это самый мощный из семейства STM32 MCU с большим количеством замечательных периферийных устройств, но в данном случае я использую только последовательный порт и GPIO. Поскольку мне нравится разгонять stm32, мне удалось достичь частоты 295MHz, прежде чем он престал работать. - ARDUINO UNO
Я не думаю, что нужно описывать эту плату. Все её знают. Плата использует ATmega328p, который является самым медленным MCU в этом сравнении. - ARDUINO LEONARDO
Это еще один вариант Arduino с процессором ATmega32, который немного быстрее, чем ATmega328p. - ARDUINO DUE
Это тоже плата Arduino, но работающая на микроконтроллере Atmel SAM3X8E, который содержит ядро ARM Cortex-M3, работающее на частоте 84 МГц. Это довольно быстрый MCU, если смотреть на его дату выпуска. - TEENSY 3.2
TEENSY - очень интересная плата, хотя и несколько дорогая. Но она совместима с библиотеками Arduino IDE, что делает ее удобной для быстрого создания прототипов и тестирования. Плата основана на контроллере с ядром Cortex-M4, и для теста я разгонял его до частоты 120 МГц. - TEENSY 3.5
Эта плата также использует процессор Cortex-M4, но он работает на более высоких частотах. Я его использовал на частоте 168 МГц. Варианты разгона для обеих плат Teensy легко выставляются с помощью плагина Teensy в Arduino IDE. - ESP8266-12E
И один беспроводной контроллер, 32-разрядный RISC L106, работающий на частоте до 160 МГц.
Простая NN
Теперь перейдем к практике. Все, что связано с этим проектом, находится в репозитории https://bitbucket.org/dimtass/machine-learning-for-embedded/src/master/
В этой серии статей я буду использовать различные части этого репо, так что все, что вы видите в нем, предназначено не только для этого первого поста.
Давайте начнем с простой NN. В этой статье мы будем использовать один нейрон с 3 входами и 1 выходом, как показано на рис. 1.
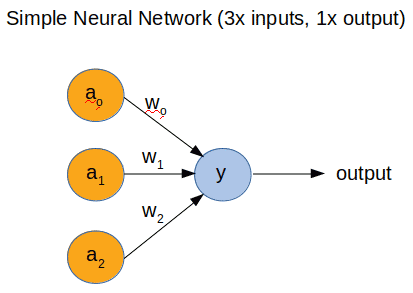
Рис. 1. Топология простейшей NN
Вы видите топологию простейшей NN. Она имеет 3 входа и 1 выход. Я не буду вдаваться в математику. В этом случае выходной сигнал описывается следующей функцией:
y = a0 * w0 + a1 * w1 + a2 * w2
Это скалярное произведение a(n) и w(n), где n = 1,2,3. Итак, a (n) - входные данные, а w (n) - так называемые веса. Веса - это просто числа, величина которых влияет на вклад каждого из a (n) на выходной результат. Чем выше w (n), тем больше a (n) влияет на y.
Выход на самом деле не у. Выходной сигнал задается сигмоидой от y, т.е. выход = сигмоида (у).
Сигмоида ограничивает выходное значение в диапазоне от 0 до 1. Таким образом, отрицательные значения y преобразуются в 0, а большие положительные значения в 1. В мире ML эта функция называется функцией активации.
Для этого проекта мы предполагаем, что a (n) является логическим сигналом (0 или 1). Поэтому, поскольку у нас есть 3 входа, все возможные комбинации входов находятся в следующей таблице:
a0 | a1 | a2 |
0 | 0 | 0 |
0 | 0 | 1 |
0 | 1 | 0 |
0 | 1 | 1 |
1 | 0 | 0 |
1 | 0 | 1 |
1 | 1 | 0 |
1 | 1 | 1 |
Для простоты вы можете думать об этих входах как о 3-х кнопках, подключенных к 3 выводам GPIO контроллера, и их состояние либо pressed, или not pressed. В зависимости от их состояния на выходе будет также логический сигнал (0 или 1).
Обучение модели
Обучение модели означает, что мы обучаем NN на основании набора входных данных, про которые мы точно знаем, в какое состояние они должны перевести выход. После обучения мы ожидаем, что NN сможет предсказать корректное выходное состояние для таких состояний входов, которых не было в данных обучения. Хотя наша модель и очень проста, обучение имеет смысл проводить не на целевой плате, а на рабочей станции (или в облаке) с большой вычислительной мощностью. (Есть и еще более простые модели, например 2 входа и 1 выход). Так что, давайте проведем обучение на рабочей станции, чтобы получить опыт использования полезных инструментов, которые облегчают рабочий процесс.
Для разработки, обучения и тестирования мы будем использовать ноутбук Jupyter. Вообще, ноутбуки Jupyter - это стандартный инструмент, который вы найдете в значительном количестве проектов на github. Самый простой способ установить Jupyter и другие необходимые нам инструменты - использовать менеджер пакетов и окружения Miniconda. Я использую Ubuntu, поэтому и приводимые в статье команды предназначены для этой ОС. Для других ОС набор команд может немного меняться. Итак, нужно:
- Скачать и установить Miniconda
- Создать окружение и установить необходимые инструменты
- # Create a new environment
- conda create -n nn-env python
- # Activate the environment
- conda activate nn-env
- # Now install those packages to that environment
- conda install -c conda-forge numpy
- conda install -c conda-forge jupyter
- conda install -c conda-forge scikit-learn
- conda install -c conda-forge tensorflow-gpu
- conda install -c conda-forge keras
Не все вышеперечисленные пакеты будут использованы в примерах в первой статье, частью из них мы воспользуемся позже.
- Клонировать git репозиторий для этого проекта и запустить Jupyter.
Не все вышеперечисленные пакеты будут использованы в примерах в первой статье, частью из них мы воспользуемся позже.
- Клонировать git репозиторий для этого проекта и запустить Jupyter.
- git clone git@bitbucket.org:dimtass/machine-learning-for-embedded.git
- cd machine-learning-for-embedded
- jupyter notebook &
Если все пройдет успешно, вы увидите веб-интерфейс от Jupyter в своем браузере. В этом веб-интерфейсе будет папка с именем jupyter_notebooks. Просто дважды щелкните по ней, и там вы найдете все блокноты для этого проекта. Для этой статьи нам понадобится блокнот "Simple python NN.ipynb". Просто нажмите на него.
То, что вы видите, - это некоторая смесь маркированного текста и кода Python. В простейшем случае мы реализуем NN только с помощью кода на Python, без использования какой-либо продвинутой библиотеки типа tensorflow или keras. Причина этого заключается в том, что сейчас мы напишем код, который позже сможем преобразовать в C и запустить тесты на разных микроконтроллерах.
Я не буду объяснять подробности работы ноутбуков Jupyter и Python. В Интернете есть множество обучающих программ, которые это сделают гораздо лучше меня.
Давайте посмотрим на открытый ноутбук.
Примечание. Если вы просто хотите просмотреть ноутбук, вам не нужно устанавливать Jupyter, вы можете просто просмотреть его в репозитории Bitbucket.
Сначала мы импортируем некоторые функции из numpy, чтобы упростить код. Затем создаем класс NeuralNetwork, который может обучать и оценивать нашу простую NN. Затем мы создаем обучающий набор для наших двоичных входов. Как мы уже видели, 3 двоичных входа имеют 8 возможных комбинаций, мы будем использовать для обучения набор из 4 состояний и предполагаем, что NN сможет предсказать состояние выхода для остальных состояний самостоятельно. Данные для обучения мы загружаем в программу в виде двух массивов - состояние входов и состояние выходов. После этого мы запускаем обучение. Обратите внимание, что веса всегда имеют случайные значения в начале обучения. Смысл обучения заключается в том, чтобы найти такие значения весов, которые максимально подходят для решения задачи. Скорее всего, когда вы запустите этот блокнот на своем компьютере, вы получите аналогичные значения весов после тренировки, хотя они также могут немного отличаться. В этом случае, если вы захотите оценить свои результаты с помощью кода, который выполняется на микроконтроллере, имейте в виду, что вам потребуется изменить веса в коде в соответствии с вашими результатами.
После обучения можно оценить модель на всех возможных входных комбинациях:
- [ 0 0 0 ] = [ 0,5 ]
- [ 0 0 1 ] = [ 0,009664 ]
- [ 0 1 0 ] = [ 0,44822538 ]
- [ 0 1 1 ] = [ 0,00786466 ]
- [ 1 0 0 ] = [ 0.99993704 ]
- [ 1 0 1 ] = [ 0,99358931 ]
- [ 1 1 0 ] = [ 0,9999925 ]
- [ 1 1 1 ] = [ 0.99211997 ]
Видно, что для значений, которые мы использовали во время обучения, прогнозы очень точны. Как я упоминал ранее в выходных данных мы получаем значения от 0 до 1. Это прогноз NN, и чем ближе он к 0 или 1, тем выше вероятность того, что выход должен иметь именно это значение. В случае, если входной набор данных совсем не похож на данные из базы обучения, выходной результат находится практически посередине, между 0 и 1.
Оценка на микроконтроллере
Теперь, когда мы разработали, обучили и проверили модель на блокноте Jupyter, мы можем ее протестировать на разных микроконтроллерах.
Смотреть мы будем не на то, что код работает, куда он денется :). Результаты могут немного отличаться от системы к системе из-за особенностей архитектуры. Но нас будет волновать производительность!
Именно ради сравнения производительности я и создал этот проект. Можно ли запустить NN в режиме реального времени? Есть ли смысл делать это на данном микроконтроллере? Могут ли относительно слабые микроконтроллеры дать нормальную производительность при работе с NN? Может быть, лучше преобразовать NN, например, в дерево решений или другой алгоритм, чтобы запустить его на MCU? Может быть стоит использовать вложенные "if-else" или поисковые таблицы, или карты Карно?
Я не буду отвечать на эти вопросы здесь, так как ответ на них зависит от множества параметров для каждого проекта и варианта использования. Но, сделав это самостоятельно, вы получите хорошее представление о производительности, возможностях и ограничениях, существующих в современных технологиях.
Код для микроконтроллеров разделен на несколько папок, stm32f103, stm32f746, esp8266, arduino due лежат в отдельных каталогах, код для остальных Arduino и Teensy лежит в папке code-arduino.
Небольшое замечание. В рабочих проектах я использую сильно урезанные библиотеки и не люблю использовать Arduino IDE или HAL. Но прототипы! Для них я нахожу использование таких библиотек очень полезным, это отличный выбор и решение, не требующее дополнительных усилий. Мы должны выбирать и использовать инструменты с умом и те, что лучше всего подходят для конкретного случая.
Подробности о том, как создать и запустить код на каждом контроллере есть в файлах README в папках проекта. Я расскажу о том как код работает.
Код
Код достаточно прост в этом примере. Функция расчета dot() и sigmoid() реализованы в файлах neural_network.h/c и вызываются из main.c. Одинаковые файлы .h и .c используются для всех микроконтроллеров. Веса задаются массивом double weights[] в main.c, а входные данные массивом double inputs[8][3]. Массивы double weights_1[32][3]и double weights_2[] можно игнорировать, они будут использоваться в следующих статьях.
Наконец, в этом примере используются еще две важные функции - benchmark_neural_network()и test_neural_network(). Они запускаются командами через последовательный порт и отправляют в него результаты. Функция теста просто распечатает прогноз для всех комбинаций входных данных, чтобы сравнить их с результатами из jupyter, а функция замера скорости выполнит прогноз и позволит измерить время выполнения с помощью осциллографа.
Поддерживаемые команды последовательного интерфейса
Чтобы упростить тестирование, я создал пару команд, которые можно передать через последовательный порт. К контроллерам stm32 можно подключаться на скорости 115 кбит/с, а для подключения к остальным контроллерам нужно использовать скорость 9600 бит/с.
Поддерживаются следующие команды (команды должны заканчиваться символом перевода строки):
TEST = < mode >
где < mode > может быть 1 или 2
Эта команда рассчитывает результаты для всех 8 возможных вариантов входных данных, выполняет прогноз с использованием рассчитанных весов, и выводит полученные результаты, которые вы можете сравнить с результатами из ноутбука Jupyter.
Режим 1 использует нейронную сеть simple1 и ее веса. Именно этот режим мы будем использовать сейчас.
Режим 2 будет использоваться в следующей статье.
Примечание: при выполнении команды TEST в среде Arduino вы получите результаты с двумя десятичными знаками. Это немного не то, что ожидается, но это свойство Serial.print, не обращайте на это внимание, на самом деле прогноз верный. С stm32 такой проблемы нет, вы получите вывод как в Python.
START = < mode >
где < mode > может быть 1 или 2 (имеет тот же смысл, что и в предыдущей команде)
Команда запускает таймер, который каждые 3 секунды запускает функцию прогнозирования, а также переключает gpio, чтобы измерить время выполнения расчета. По умолчанию прогнозирование выполняется на первом входном наборе [0 0 0]. Это не имеет значения, поскольку не влияет на время вычислений, но вы можете изменить набор в коде, если захотите. Естественно, режим 1 намного быстрее, чем режим 2, который мы рассмотрим в следующей статье.
STOP
Команда STOP просто останавливает таймер, который был запущен командой START = <mode>.
Производительность
Лучший способ измерить время, необходимое для выполнения кода - это использовать осциллограф и выход gpio. Вы можете установить высокий уровень перед началом функции, затем выполнить функцию и переключить выход в низкий уровень. С помощью осциллографа вы можете узнать точное время выполнения.
Хотя в этом подходе есть подвох! Переключение выхода также занимает некоторое время, и это время отличается для разных устройств и даже для библиотек gpio для одного и того же контроллера. По этой причине в коде выход переключается два раза перед запуском функции прогнозирования. Таким образом, вы можете узнать время, которое необходимо на выполнение этих переключений и вычесть среднее время переключения из времени, которое потребовалось на операцию прогнозирования. Таким образом, если время выполнения двух переключений Tt, а время между состояниями HIGH и LOW функции прогнозирования Thl, то время выполнения прогноза составит Tp = Thl - (Tt/2).
Такого подхода должно быть достаточно, чтобы исключить из обработки любые задержки, связанные с переключением выходов в разных MCU.
Примечание: я включил все осциллограммы в папку скриншотов в репозитории. Там образом, вы можете посмотреть на реальные задержки для каждого микроконтроллера. Для имен файлов в папке скриншотов используется следующий шаблон <mcu>-<NN topology>-<frequency>-<capture>.png.
Т.е. для teensy 3.2 и простой нейронной сети будет называться "teensy_3.2-simple1-120MHz-predict.png".
Вот скриншоты для двух контроллеров stm32f103 и arduino uno, а ниже будут таблицы с результатами.
stm32f103 @ 128 МГц, время переключения = 290 нс
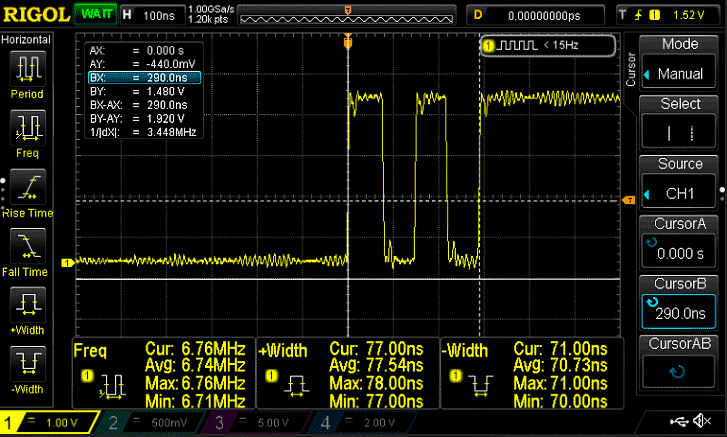
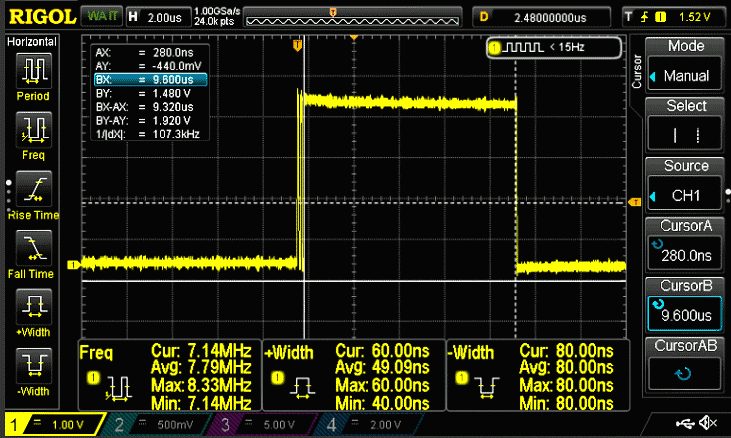
stm32f103 @ 128 МГц, время предсказания = 9,38 мкс
Arduino Uno @ 8 МГц, время переключения = 15,5 мкс
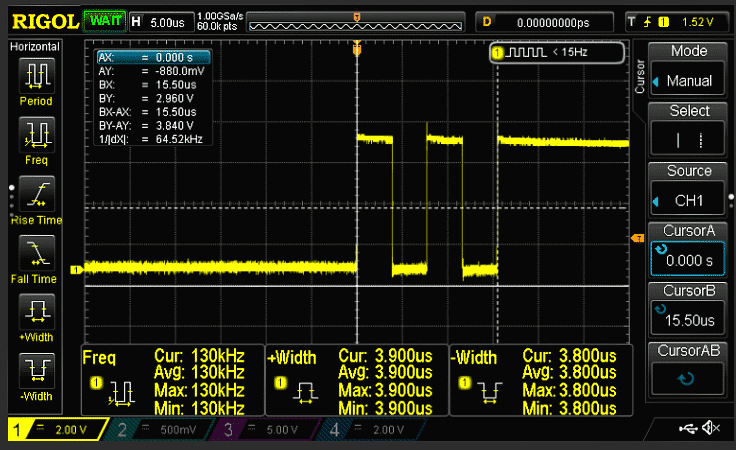
Arduino Uno @ 8MHz время предсказания = 114,4 мкс
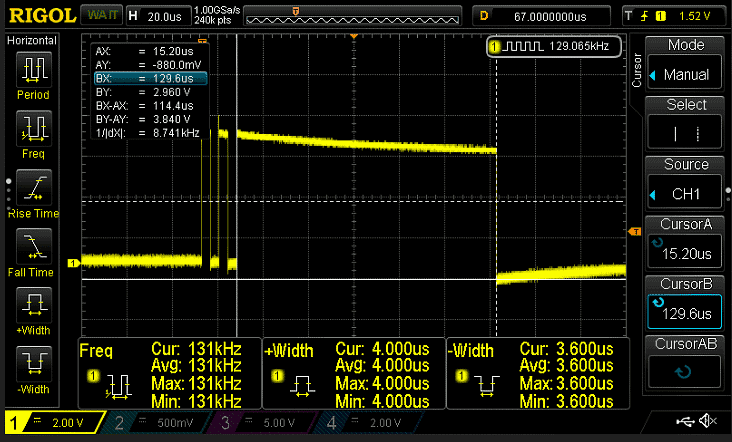
А теперь конкретные результаты:
MCU | Время переключения выхода (мкс) | Время прогнозирования (мкс) |
stm32f103 @ 72 МГц | 0,512 | 16,9 |
stm32f103 @ 128 МГц | 0,290 | 9,38 |
Arduino Uno @ 8 МГц | 15,5 | 114,4 |
Ard. Leonardo @ 16 МГц | 21 | 116 |
Arduino DUE @ 84 МГц | 8,8 | 18,9 |
ESP8266-12E @ 160 МГц | 1,58 | 15,64 |
Teensy 3.2 @ 120 МГц | 0,830 | 11,76 |
Teensy 3.5 @ 168 МГц | 0,572 | 8,84 |
stm32f746 @ 216 МГц | 0,157 | 4,86 |
stm32f746 @ 295 МГц | 0,115 | 3,58 |
Естественно, чем выше частота, тем выше производительность (в результатах не учтено время переключения выходов). Также обратите внимание, хотя Teensy 3.5 имеет лучшую производительность по сравнению с stm32f103 @ 128 МГц, время переключения выводов почти вдвое хуже … Естественно, это следствие использования библиотек arduino для включения/выключения вывода. Ну и конечно, разогнанная плата stm32f746 @ 295MHz является самой быстрой.
Еще одно замечание, не относящееся к NN. Если посмотреть на соотношение (время предсказания)/ (время переключения вывода), то вы получите интересные цифры. Давайте посмотрим на следующую таблицу:
MCU | (время предсказания)/(время переключения вывода) |
stm32f103 @ 72 МГц | 33 |
stm32f103 @ 128 МГц | 32,34 |
Arduino Uno @ 8 МГц | 7,38 |
Ard. Leonardo @ 16 МГц | 5,52 |
Arduino DUE @ 84 МГц | 2,14 |
ESP8266-12E @ 160 МГц | 9,89 |
Teensy 3.2 @ 120 МГц | 14,16 |
Teensy 3.5 @ 168 МГц | 15,45 |
stm32f746 @ 216 МГц | 31,13 |
Таблица показывает, как библиотеки arduino влияют на общую производительность. Честно говоря, код NN не зависит от библиотек, так как это простой C-код. Но обычно ваш MCU также выполняет другие задачи, а не только запускает NN; следовательно, все остальное, что делает процессор, влияет на производительность NN, особенно если в коде используются раздутые библиотеки. В этом случае мы просто переключали выход и запускали таймер в фоновом режиме, больше ничего. (На самом деле stm32f103 запускает еще несколько задач, но это не сказывается на производительности). Поведение Arduino DUE абсолютно необъяснимо, но оно наблюдается совершенно стабильно. Я не изучал причины этого. Тем не менее, эта таблица подтверждает мое мнение, что создание прототипов полностью отличается от разработки. Прототипирование является доказательством концепции, и после этого переход на следующий уровень разработки обеспечит производительность.
Выводы
Эта статья показывает, что мы можем реально спроектировать, обучить, оценить и протестировать NN используя Jupyter и python, а затем запустить сеть на небольшом MCU. И это здорово! Но использование такого большого количества ресурсов на небольших микроконтроллерах для запуска NN с 3 входами и 1 выходом конечно не оправдано!
С другой стороны, мы можем использовать эту NN для приложений реального времени! Хорошо, не смейтесь. Я знаю, что этот пример практически бесполезен, но даже 114.4мкс у Arduino приемлемо для приложений реального времени. Конечно, это зависит от требований к решению. Но подумайте о кнопках!
Хотя, подождите. Возникает другой вопрос. Если входы являются кнопками, то почему бы не создать вложенную конструкцию из if и обрабатывать ее намного быстрее?
Или создать справочную таблицу? Или создать карту Карно для входов/выходов и сократить ее до пары логических операций. Эти решения будут работать очень быстро!
Но как я уже сказал, это очень упрощенный пример и предназначен только для тестирования, а не для того, чтобы делать что-либо действительно полезное. Но с другой стороны, если вместо 3 входов у нас было 128? Или 512? Тогда было бы действительно сложно составить карту Карно и упростить ее. А если бы потом пришлось еще что-то изменить во входных или выходных наборах? Тогда пришлось бы очень сильно править код. Возможно, справочная таблица была бы хорошим решением. Но она будет стоить места в RAM или FLASH, и не известно, что потребует больше места - NN или таблицы. Так что в любом случае вам придется сравнить, сколько потребуется места для каждого решения, и какую производительность это решение обеспечит.
Важно понимать, что ML не решает все наши инженерные проблемы. Это инструмент, который, позволит решить некоторые проблемы, которые раньше было очень сложно решить. И, в некоторых случаях, он сможет обеспечить дополнительную гибкость по сравнению с теми решениями, которые мы сейчас используем.
В следующей статье мы исследуем работу более сложной сети с 3-входами, скрытым слоем с 32 узлами и 1-выходом.
Источник: https://www.stupid-projects.com
Опубликовано: 10.03.2020