

Использование специализированных функциональных блоков в eFPGA для повышения производительности и уменьшения габаритов ASIC и SOC
FPGA (ПЛИС) широко используются разработчиками уже более трех десятков лет. Популярность FPGA объясняется двумя факторами: производительностью и гибкостью. Многие задачи, могут решаться программным способом с помощью микропроцессоров или микроконтроллеров. Однако если те же задачи решать не на программном, а на аппаратном уровне с привлечением специализированных аппаратных блоков, то можно существенно увеличить эффективность вычислений. Именно по этой причине разработчики переходят на FPGA или разрабатывают ASIC/ SoC.
Однако стоит понимать, что переход на ASIC имеет смысл только в том случае, если в дальнейшем не предполагается каких-либо изменений. В наши дни такая стабильность встречается не часто. Стандарты меняются. Если в процессе разработки в ASIC были реализованы неправильные алгоритмы, то придется полностью перерабатывать чип.
Разработчики часто прибегают к услугам ПЛИС, если требуется обеспечить высокую скорость обработки и при этом сохранить гибкость и возможность быстрого изменения рабочих алгоритмов. В настоящее время совместное использование на одной печатной плате процессора (или микроконтроллера) и ПЛИС является вполне обыденным решением. Процессор выполняет большую часть программы встроенной системы, в то время как FPGA используется для ускоренного решения задач, которые требуют повышенной производительности.
К сожалению, если процессор и FPGA физически расположены в разных микросхемах, то взаимодействие между ними может стать слабым местом всей системы. В таких случаях, независимо от того, насколько быстра связь между этими двумя устройствами, им приходится общаться друг с другом через проводники печатной платы.
Для взаимодействия между процессором и FPGA на протяжении многих лет используются специальные высокоскоростные протоколы и интерфейсы. Изначально для этих целей чаще применяли параллельные интерфейсы. В последнее время наиболее распространенным интерфейсом стал PCI Express (PCIe) – высокоскоростной последовательный протокол, обеспечивающий быструю передачу данных. Однако, не смотря на высокую скорость, PCIe вносит дополнительную задержку, связанную с сериализацией данных, их передачей и последующей десериализацией.
Встраивайте FPGA в микросхемы ASIC или SoC
Альтернативой для обычных ПЛИС становятся встраиваемые FPGA – eFPGA, которые интегрируются в состав ASIC или SoC и выполняют функции программируемых аппаратных ускорителей. При этом разработчик получает возможность напрямую подключать eFPGA к внутренним шинам ASIC. Прямое подключение к внутренним шинам ASIC обеспечивает снижение задержки при передаче данных между ПЛИС и процессором до 10 нс, в то время как при использовании PCIe задержка составляла от 1 до 10 мкс (рис. 1).
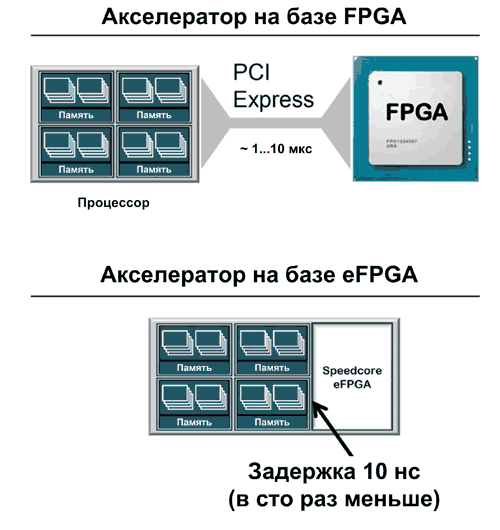
Рис. 1. eFPGA в ASIC обеспечивает снижение задержки при передаче данных между ПЛИС и процессором примерно до 10 нс, что в 100 раз меньше по сравнению с задержкой при использовании отдельных микросхем
Добавление одной или нескольких eFPGA в ASIC или SoC устраняет узкие места в каналах передачи данных. Кроме того, количество связей между встроенным процессором (процессорами) и встроенной eFPGA может быть значительно выше, чем при использовании отдельных микросхем.
Во многих SoC процессорное ядро ARM взаимодействует с другими встроенными блоками с помощью шины Advanced eXtensible Interface (AXI). При этом разработчик может легко использовать 128-битную шину AXI для подключения целого комплекса процессоров к eFPGA. Если в приложении требуется более высокая пропускная способность, то следует добавить две, четыре или даже больше 128-битных шин AXI для управления аппаратными ускорителями, реализованными на базе eFPGA.
У eFPGA есть еще одно важное преимущество перед связкой, состоящей из дискретных микросхем процессора и FPGA. Обычная FPGA отделена от процессора не только физически, но и логически, поэтому для буферизации больших блоков данных ей требуется собственная SRAM или SDRAM (DDR).
Это означает, что прежде чем начать обработку данных процессор или контроллер прямого доступа к памяти (DMA) должны переместить блок исходных данных из памяти процессора в память FPGA. После обработки выходные данные должны быть переданы обратно из памяти FPGA в память процессора. Задержка, связанная с пересылкой данных, может оказаться чрезвычайно большой.
Благодаря прямой связи между eFPGA и памятью процессора необходимость в передаче данных отпадает. Вместо пересылки блоков данных процессор передает eFPGA указатель на область памяти, и eFPGA практически мгновенно переходит к стадии обработки. Когда eFPGA завершает свою работу, она передает процессору указатель на область памяти, в которой хранится результат.
Использование eFPGA вдвое снижает энергопотребление по сравнению с использованием отдельной микросхемы FPGA. Дело в том, что у FPGA значительная площадь кристалла занята весьма «прожорливыми» портами ввода-вывода IO, которые необходимы для подключения внешних микросхем и, в том числе, процессора. В то же время eFPGA размещена на кристалле ASIC или SoC и может напрямую обмениваться данными с другими встроенными IP-блоками без участия портов ввода-вывода, так как при прямом подключении нет необходимости в согласовании уровней напряжения или других параметров.
Таким образом, стоимость eFPGA оказывается гораздо меньше, чем стоимость корпусных FPGA, в первую очередь по той причине, что площадь кристалла eFPGA значительно меньше. Кроме того, стоимость снижется благодаря отказу от корпусного исполнения, сокращения места, занимаемого на печатной плате, уменьшения числа внешних компонентов.
Архитектура eFPGA и специализированые блоки
Столбцовая архитектура уже давно была признана наиболее эффективным способом компоновки ПЛИС. Такая организация FPGA подразумевает объединение различных функций по колонкам. Таким образом, выделяется один или несколько столбцов для таблиц истинности (LUT), один или несколько столбцов для памяти и один или несколько столбцов для DSP-процессоров. Взаимодействие между столбцами организуется с помощью программируемой матрицы соединений.
Набор функциональных блоков, входящих в состав микросхемы ПЛИС, определяет производитель. При этом производитель рассчитывает на широкую аудиторию пользователей. По этой причине практически невозможно создать ПЛИС с универсальным набором встроенных блоков, который был бы оптимальным для каждого конкретного приложения. Однако при выборе ядра eFPGA для ASIC или SoC, разработчик может самостоятельно определить оптимальный состав блоков в соответствии с требованиями конечного приложения и отказаться от всего лишнего.
Есть еще одно важное различие между FPGA и eFPGA. При работе с eFPGA пользователь не ограничен стандартными функциональными блоками (LUT, памятью и DSP). Он может самостоятельно создавать специализированные пользовательские блоки, которые улучшат производительность при решении определенных задач и помогут еще больше уменьшить размер кристалла.
Специализированные блоки улучшают производительность
Проиллюстрируем преимущества использования специализированных блоков на примере eFPGA Achronix Speedcore. Рассмотрим систему потоковой обработки пакетов с пропускной способностью 400 Гбит/с. Столь высокую скорость обработки чрезвычайно сложно обеспечить даже с помощью eFPGA, так как возникают огромные проблемы с временными задержками. Решить задачу «в лоб» можно за счет использования широких внутренних шин с разрядностью 1024 или даже 2048 бит.
Другим решением становится добавление специализированных блоков. Специализированные блоки позволяют уйти от сверхшироких шин и обеспечить передачу данных с самой высокой скоростью без участия LUT или программируемых межсоединений.
В рассматриваемом примере используется специально созданный блок, выполняющий извлечение и вставку отдельных полей пакетов (PX). Конвейер таких блоков обеспечивает заданную пропускную способность 400 Гбит/с (рис. 2). Логика, реализованная в eFPGA, выдает команды блокам PX для захвата и извлечения полей пакетов, например, заголовков. Далее eFPGA обрабатывает извлеченные поля пакетов и повторно вставляет модифицированные данные обратно в поток пакетов с помощью других блоков PX.
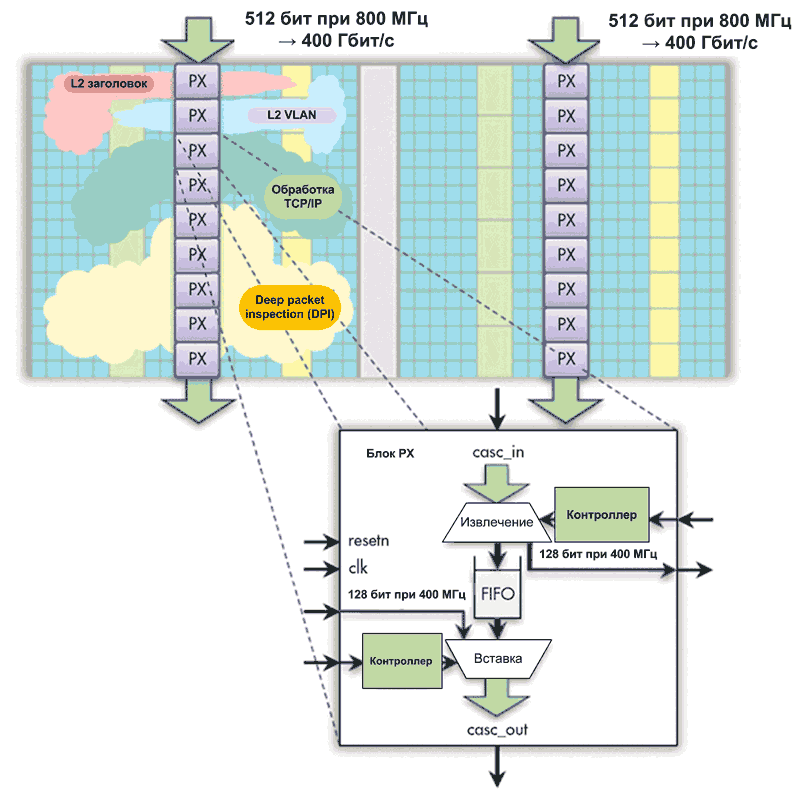
Рис. 2. Добавление специализированных блоков в eFPGA позволяет обрабатывать пакетный трафик со скоростью 400 Гбит/с, что было бы невозможно без использования чрезвычайно широких (1024-битных или 2048-битных) шин
Использование специализированных блоков eFPGA позволяет достигать чрезвычайно высокой производительности, которая оказывается физически недостижимой для современных ПЛИС.
Эффективность традиционных ПЛИС оказывается как минимум в 10 раз ниже, чем у ASIC. Это является неизбежной расплатой за гибкость, которую ПЛИС дают разработчику. В то же время встраиваемые eFPGA придают ASIC точно такую же гибкость, при том, что все остальные преимущества ASIC, в том числе производительность, сохраняются.
Специализированные блоки позволяют эффективнее использовать eFPGA там, где это действительно нужно. Кроме того, они помогают оптимизировать структуру схемы за счет перевода блоков в неизменяемую часть ASIC. Используя ASIC-блоки для реализации функций в структуре eFPGA, разработчик может достигать необходимой производительности и сохранять гибкость, присущую eFPGA.
FPGA против eFPGA: реальные отличия
Если внимательно рассмотреть фотографию кристалла ПЛИС, то можно заметить, что цифровое ядро ПЛИС (LUT, память и DSP) занимает около половины общей площади кристалла. Другая половина обычно отводится для размещения программируемых портов ввода-вывода.
Программируемые порты ввода-вывода играют чрезвычайно важную роль для FPGA. Они позволяют разработчикам подключать ПЛИС к другим устройствам, в том числе к микропроцессорам, памяти, ASIC и даже к другим ПЛИС. Очевидно, что число портов ввода-вывода должно быть достаточно большим, в результате чего приходится выделять им так много места на кристалле. В отличие от обычных FPGA, встраиваемые eFPGA не нуждаются в портах ввода-вывода, так как они напрямую подключаются к другим блокам, входящим в состав ASIC.
Кроме того что порты ввода-вывода занимают значительную площадь на кристалле, на их долю также приходится существенный вклад в общее потребление. Очевидно, что из-за отсутствия портов ввода-вывода, встраиваемые eFPGA оказываются свободными от этого недостатка.
Далее следует коснуться системного интерфейса. Многие аппаратные ускорители на основе ПЛИС имеют стандартный системный интерфейс, который не меняется от одной итерации проекта к другой. Например, интерфейс аппаратного ускорителя с процессором обычно не меняется при появлении следующих версий прошивок. Меняются только функции и реализация отдельных блоков. Следовательно, нет необходимости в том, чтобы размещать системный интерфейс в eFPGA. Эту часть проекта будет логично вынести в состав неизменяемой части ASIC, что позволит дополнительно повысить производительность и уменьшить площадь кристалла.
Использование специализированных блоков eFPGA позволяет в шесть раз уменьшить площадь, занимаемую на кристалле по сравнению с аналогичной реализацией на ПЛИС (рис. 3).
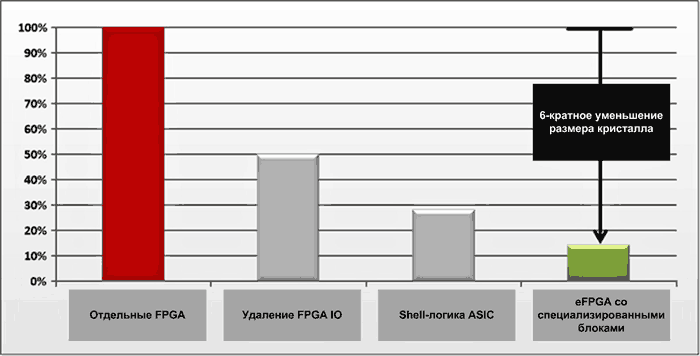
Рис. 3. Применение специализированных блоков eFPGA, отказ от портов ввода-вывода, перенос системного интерфейса в ASIC
Таким образом, добавление специализированных блоков в eFPGA обеспечивает эффективное использование площади кристалла ASIC и достижение высокой производительности при сохранении гибкости аппаратного программирования.
Опубликовано: 01.04.2019